All | Text | Date | Number | Aggregate | Filters | Lookups | Period | Queries | Math | System | Financial | Conditional | Common | Special
Functions for text conversion
These functions perform an operation on text values, and return a derivative of the original values. You can use these to convert text values in imports, reports, or models.
ACRONYM ❖ XLReporting
Returns an upper case abbreviation formed by using the initial letters and digits of the given word or phrase. Spaces and special characters are ignored.
ACRONYM(data)
Examples:
ACRONYM("trial balance report") = "TBR"
ALPHANUM
Returns a text string with all characters removed from the given text string that are not numeric (digits 0-9) and/or not a letter (a-z or A-Z). Excessive spaces are removed.
This function is useful for cleaning imported data such as account names or codes by removing symbols and extra spaces. It helps standardize values for reporting or matching.
ALPHANUM(data)
Examples:
ALPHANUM("Account Nr: #400.10;") = "Account Nr 40010"
CHANGE ❖ XLReporting
Replaces all occurrences of the given search text (old) within the given text string (data) with the given replacement text (new).
With the optional type parameter you can also change multiple characters or a list of values in one operation.
This function is useful for correcting terminology, reformatting labels, or renaming codes during data import or transformation. It's a flexible tool for text cleanup.
Please note that this function uses regular expression searches, so special characters require a prefix character. This is usually a single backslash \ but XLReporting requires 2 backslashes, so \\.
If you want to replace text based on a certain position, you should use the REPLACE function.
CHANGE(data, old, new, type)
type:
0 = standard (default)
1 = change any single character
2 =
change each string in a cell range or comma-delimited list of values
Example:
data = "this text is an (example)"
CHANGE(data, "this", "that")
= "that text is an (example)"
CHANGE(data, "()", "", 1) = this text is an example
CHANGE(data,
"this,is,an", "*", 2) = * text * * (example)
CHAR
Returns the character that corresponds to the given numeric value.
This function is useful for generating special characters (like line breaks or symbols) in dynamic text, particularly in formatted outputs or custom messages.
CHAR(data)
Example:
CHAR(65) = "A"
CLEAN
Returns a text string with all whitespaces and nonprintable characters removed from the given text.
This function is useful for sanitizing messy data before using it in reports or lookups, especially when importing from external sources.
CLEAN(data)
Example:
CLEAN("A B C ") = "ABC"
CODE
Returns the numeric code for the given start position within the given text string. If you don't provide the character position, the first character will be used.
This function is useful for identifying control characters or debugging formatting issues in imported or encoded text.
CODE(data, start)
Example:
CODE("ABC", 2) = 66
CONCAT
Joins together two or more text strings in cell ranges, data arrays, or comma-delimited lists of values. You may specify multiple ranges. With the optional type parameter you can ignore comma's in texts (to prevent such texts from being treated as comma-delimited lists of values).
This function is useful for assembling custom descriptions, full names, addresses, or notes from multiple fields into a single readable output.
CONCAT(data, data, .., type)
type:
0 = standard (default)
1 = ignore comma's in texts
Examples:
data = "this text"
CONCAT(data, " and more") =
"this text and more"
CONCAT(A1:A3, B1:B3)
EXACT
Returns true if two text strings are exactly the same, else false. With the optional type parameter you can ignore case-sensitivity, spaces, and special characters.
This function is useful for validating consistency in data entry or reconciling values that may differ in casing or formatting.
EXACT(data, text, type)
type:
0 = exact match (default)
1 = ignore case-sensitivity, spaces, and
special characters
Examples:
data = "this text"
EXACT(data, "This Text!") = false
EXACT(data,
"This Text!", 1) = true
INDENT ❖ XLReporting
Indents the given text string to the given level (0-9).
This function enables you to dynamically indent text, based on some condition, for example a value in the cell or comparison against another cell. Level 0 is no indentation, and each next level (up to 9) indents the text with 20px.
This function is useful for dynamically formatting hierarchical lists (e.g. account groups or cost centers) in reports for better readability.
INDENT(data, level)
Example:
INDENT("example text", 1)
JOIN ❖ XLReporting
Joins together non-zero values or non-empty text strings in cell ranges, data arrays, or comma-delimited lists of values, merged with the given separator (char). You may specify multiple ranges.
This function is useful for formatting arrays or concatenating lists (e.g. tags, departments, products) with commas, slashes, or custom separators.
If you want to include empty text strings, you should use the TEXTJOIN() function instead.
This function is the reverse of the SPLIT function.
JOIN(data, data, .., char)
Examples:
JOIN("a, b, c", "/") = "a/b/c"
JOIN(A2:A5, A20:A22, ";")
LEFT
Returns a specified number of characters from the start of the given text string.
This function is useful for parsing codes, identifiers, or prefixes when splitting text into components.
LEFT(data, number)
Example:
data = "this text"
LEFT(data, 3) = "thi"
LEN
Returns the length (i.e. the number of characters) of the given text string.
This function is useful for validating input lengths (e.g. tax numbers, IDs) or flagging values that exceed required limits.
LEN(data)
Example:
data = "this text"
LEN(data) = 9
LOWER
Converts all characters in the given text string to lower case.
This function is useful for normalizing text values to ensure consistent matching or display, especially in lookups or case-sensitive systems.
LOWER(data)
Example:
data = "THIS TEXT"
LOWER(data) = "this text"
MERGE ❖ XLReporting
Merges the values from a key-value data range into placeholders inside the given text. The data range needs to consist of 1 or more rows with 2 columns, the 1st column being the key and the 2nd column being the associated value. The text can contain multiple instances of key embedded between square brackets (e.g. "The revenue is [amount]" ).
Please note that this function does not follow the cell format (i.e. number and date format) of the placeholder value. You have to use the TEXT() function in the placeholder value cell to set the desired presentation format for amounts and dates.
You can also use 2 special placeholders for text markup: [br] for a line break and [li] for a list of bullet points.
This function is useful for generating custom text such as narrative reports, explanations, or messages where values are merged into a predefined sentence.
MERGE(data, text)
Examples:
=MERGE(A2:B5,"We close the year with revenue of $ [revenue]
and costs of $ [costs].")
=MERGE(A2:B5, IF(B6>1000, D1, D2))
You can dynamically retrieve the text from a data query:
=MERGE(A2:B5, DGET("ModelA", 1))
=MERGE(A2:B5, DGET(IF(B6>1000, "ModelA", "ModelB"), 1))
Equally, you can retrieve the values from a data query (it must return exactly
2 columns). For example:
=MERGE(DRANGE("2019", 1), "The revenue is [amount]")
=MERGE(DRANGE("", 1, 0, -1), "The revenue is [amount]")
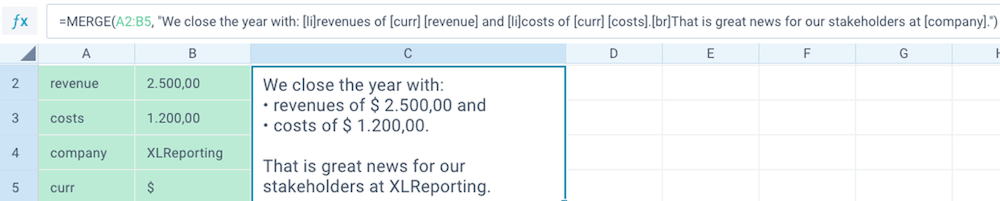
- Keys are case-sensitive and can only contain letters, numbers, and space (no special characters). Values can contain anything.
- The data range does not need to be sorted. It can be placed in hidden columns or on a hidden sheet.
- As this function behaves the same as any other function, you can combine it with other functions, values, or cell references.
MID
Returns a specified number of characters starting at the given start position within the given text string. The number parameter is optional.
This function is useful for pulling parts of structured codes (like region or department codes) when they appear at fixed positions.
MID(data, start, number)
Example:
data = "this text"
MID(data, 2, 3) = "his"
PROPER
Converts all separate words in the given text string to proper case (meaning: letters that do not follow another letter in upper case and all other characters in lower case). The optional split parameter will separate capitalized words in the given text string with a space.
This function is useful for formatting names, labels, or descriptions in reports to appear polished and professional.
PROPER(data, split)
type:
0 = convert separate words to proper case (default)
1 = separate capitalized words with a space
Example:
data = "some example text"
PROPER(data) = "Some Example
Text"
data = "SomeExampleText"
PROPER(data) = "Some Example Text"
REDUCE ❖ XLReporting
Returns the first value that exists (partially or entirely) in a text, cell range, data array, or comma-delimited list of values, else returns false. This function can be useful to convert (reduce) complex text values into simpler terms.
This function is useful for mapping product types, keywords, or category tags into simplified labels for grouping or classification.
REDUCE(data, values, values, ..)
Example:
data = "www.google.com, www.google.nl, https://googleapi.com"
REDUCE(data,
"google", "apple") = "google"
REGEX ❖ XLReporting
Returns the result of matching a text against a sequence of characters that specifies a search pattern. This can be used to test, extract, or substitute text.
Regular expressions are powerful text search patterns, which are universally standardized. You can find more information, a comprehensive reference, and a useful tool for experimentation, at https://regex101.com. Please note: special characters in search patterns require a prefix character. This is usually a single backslash \ but XLReporting requires 2 backslashes, so \\. See the examples below.
This function is useful for complex text manipulation such as validating formats (e.g. email, invoice numbers), extracting values, or anonymizing data.
REGEX(data, regex, flags, type, option)
Common regex patterns:
\\w = find a word character
\\w+ = find entire words, consisting of 1 or more word characters
\\d = find a digit
\\d+ = find numbers, consisting of 1 or more digits
\\s = find a whitespace character
\\t = find a tab character
\\n = find a newline character
[a-z] = find any character between the brackets
[^a-z] = find any character NOT Between the brackets
(a|b) = find any of the given words or characters
^a = find the pattern at the start of the data
a$ = find the pattern at the end of the data
Flags:
g = global match (find all matches, don't stop after the first match)
i = case-insensitive match
m = multiline match
type:
0 = test if the pattern matches, and return true or false (default)
1 = extract the n-th element (specified by the number in option) that matches the
pattern
2 = substitute the text that matches the pattern by the text specified in option
Examples:
data = "this shop has 34 products and 3 windows"
REGEX(data,
"has") = true
REGEX(data, "\\w+", "g", 1, 4) = "products"
REGEX(data, "\\d+", "g", 1, 1)
= 34
REGEX(data, "products", "gi", 2, "items") = "this shop has 34 items and 3 windows"
REPLACE
Replaces all or part of the given text string with another string new (at the given start position), for the given number of characters. The start and number parameters are optional.
This function is useful for modifying structured codes or values based on position, which is ideal for reformatting document IDs, account numbers, or standardizing reference formats.
If you want to replace text based on a search text, you should use the CHANGE function.
REPLACE(data, start, number, new)
Example:
data = "this text"
REPLACE(data, 1, 4, "that") =
"that text"
REPT
Returns a text string with the given text string repeated for the given number of times.
This function is useful for visual formatting or creating mock data in financial models (e.g. repeating dashes or patterns for alignment).
REPT(data, number)
Example:
data = "ab."
REPT(data, 3) = "ab.ab.ab."
RIGHT
Returns a specified number of characters from the end of a given text string.
This function is useful for parsing trailing codes, such as cost center suffixes or last digits of IDs or invoice numbers.
RIGHT(data, number)
Example:
data = "this text"
RIGHT(data, 3) = "ext"
SEARCH
Returns the first position of the given text string or character within another given data string. You can optionally specify a start position.
This function is useful for locating terms, detecting content, or validating expected labels or codes within descriptions.
SEARCH(data, text, start, type)
type:
0 = case-insensitive search (default)
1 = case-sensitive search
Example:
data = "this text"
SEARCH(data, "text", 1) = 6
SPLIT
Splits the given text string into separate elements, based on the given delimiter character, and returns the element at the given index (starting at 1). You can pass a negative index to return an element counting backwards from the end.
This function is useful for breaking apart structured labels like "Region/Department/Account" or processing lists within cells for granular analysis.
This function is the reverse of the TEXTJOIN function.
SPLIT(data, delimiter, index)
Examples:
data = "apple/orange/banana"
SPLIT(data, "/", 2) =
"orange"
SPLIT(data, "/", -3) = "apple"
STRIP
Returns a text string with all characters removed from the given text string that are not numeric (digits 0-9) and/or not a letter (a-z or A-Z). Excessive spaces are removed.
This function is useful for cleaning raw data such as codes, references, or names by removing symbols or restricting to digits, letters, or casing.
STRIP(data, type)
type:
0 = return digits and letters (default)
1 = return only numeric digits
2 = return only letters (case-insensitive)
3 = return only lowercase letters
4 = return only uppercase letters
Examples:
STRIP("Account Nr: #400.10;") = "Account Nr 40010"
STRIP("Account!Nr#400.10;",
1) = 40010
SUBSTITUTE
Substitutes all occurrences of the given search text (old) within the given text string (data) with the given replacement text (new).
If you want to replace text based on a certain position, you should use the REPLACE function.
This function is useful for fixing terminology in imported data sets or adjusting repeated terms in names or labels.
Please note that this function uses regular expression searches, so special characters require a prefix character. This is usually a single backslash \ but XLReporting requires 2 backslashes, so \\.
SUBSTITUTE(data, old, new)
Example:
data = "this text"
SUBSTITUTE(data, "this", "that")
= "that text"
TEXT
Converts the given value into text, using a user-specified format (as per the user profile). You can use this function if you want to represent values as formatted text (for example, when you want to concatenate it with other text).
This function is useful for presenting financial values with specific formatting in reports or for concatenating numeric values into readable summaries.
TEXT(data, type)
type:
"0" = no decimals (default)
"0.0" = 1 decimals
"0.00" = 2 decimals
"0.0%" = percent with 1 decimal
1-9 = the number of decimals (n = 1 through 8)
"D" = date
"Zn" = pad with leading zeros (n = fixed length)
Examples:
data = 4"
TEXT(data, "0.00") = 4.00
TEXT(data, 2) =
4.00
TEXT(data,
"0.0%") = "4.0%"
TEXT(data, "Z6") = "000004"
You can use this function in imports, reports, and models. However, in models the visual presentation of numeric values is determined by the "cell format", so please make sure your cell format is set accordingly.
TEXTAFTER
Splits the given text string into separate elements, based on the given delimiter character, and returns a text string with everything after the requested element at the given index (starting at 1). You can pass a negative index to return an element counting backwards from the end.
The selected elements are concatenated into a text string, based on the given join delimiter (which can be the same as the split delimiter, or different, or nothing).
This function is useful for retrieving trailing components in hierarchical text values like category trees or nested labels.
TEXTAFTER(data, delimiter, index, join)
Examples:
data = "apple/orange/banana/berry"
TEXTAFTER(data, "/", 2, ";")
= "banana;berry"
TEXTAFTER(data, "/", 2) = "bananaberry"
TEXTBEFORE
Splits the given text string into separate elements, based on the given delimiter character, and returns a text string with everything before the requested element at the given index (starting at 1). You can pass a negative index to return an element counting backwards from the end.
The selected elements are concatenated into a text string, based on the given join delimiter (which can be the same as the split delimiter, or different, or nothing).
This function is useful for isolating leading values such as country codes, region names, or category headers.
TEXTBEFORE(data, delimiter, index, join)
Examples:
data = "apple/orange/banana/berry"
TEXTBEFORE(data, "/", 2,
";")
= "apple;orange"
TEXTBEFORE(data, "/", 2) = "appleorange"
TEXTJOIN
Joins together text strings in cell ranges, data arrays, or comma-delimited lists of values, merged with the given separator (char). You may specify multiple ranges. This function will also include empty text strings. If you want to exclude those, you should use the JOIN() function instead.
This function is useful for compiling structured lists (e.g. cost centers, projects) into one field for cleaner reporting or dashboard displays.
This function is the reverse of the SPLIT function.
TEXTJOIN(data, data, .., char)
Examples:
TEXTJOIN("a, b, c", "/") = "a/b/c"
TEXTJOIN(A2:A5, A20:A22,
";")
TEXTSPLIT
Splits the given text string into separate elements, based on the given delimiter character, and returns the element at the given index (starting at 1). You can pass a negative index to return an element counting backwards from the end.
This function is useful for text parsing, especially when analyzing coded values or transforming list-based data into discrete fields.
This function is an alias of the SPLIT function, and the reverse of the TEXTJOIN function.
TEXTSPLIT(data, delimiter, index)
Examples:
data = "apple/orange/banana"
TEXTSPLIT(data, "/", 2) =
"orange"
TEXTSPLIT(data, "/", -3) = "apple"
TRIM
Removes redundant spaces and spaces at the start and end of the given text string.
This function is useful for text parsing, especially when analyzing coded values or transforming list-based data into discrete fields.
TRIM(data)
Example:
data = " this text "
TRIM(data) = "this text"
UPPER
Converts all characters in the given text string to upper case.
This function is useful for standardizing casing in identifiers or text labels, especially when matching entries across systems.
UPPER(data)
Example:
data = "this text"
UPPER(data) = "THIS TEXT"